OPENAI
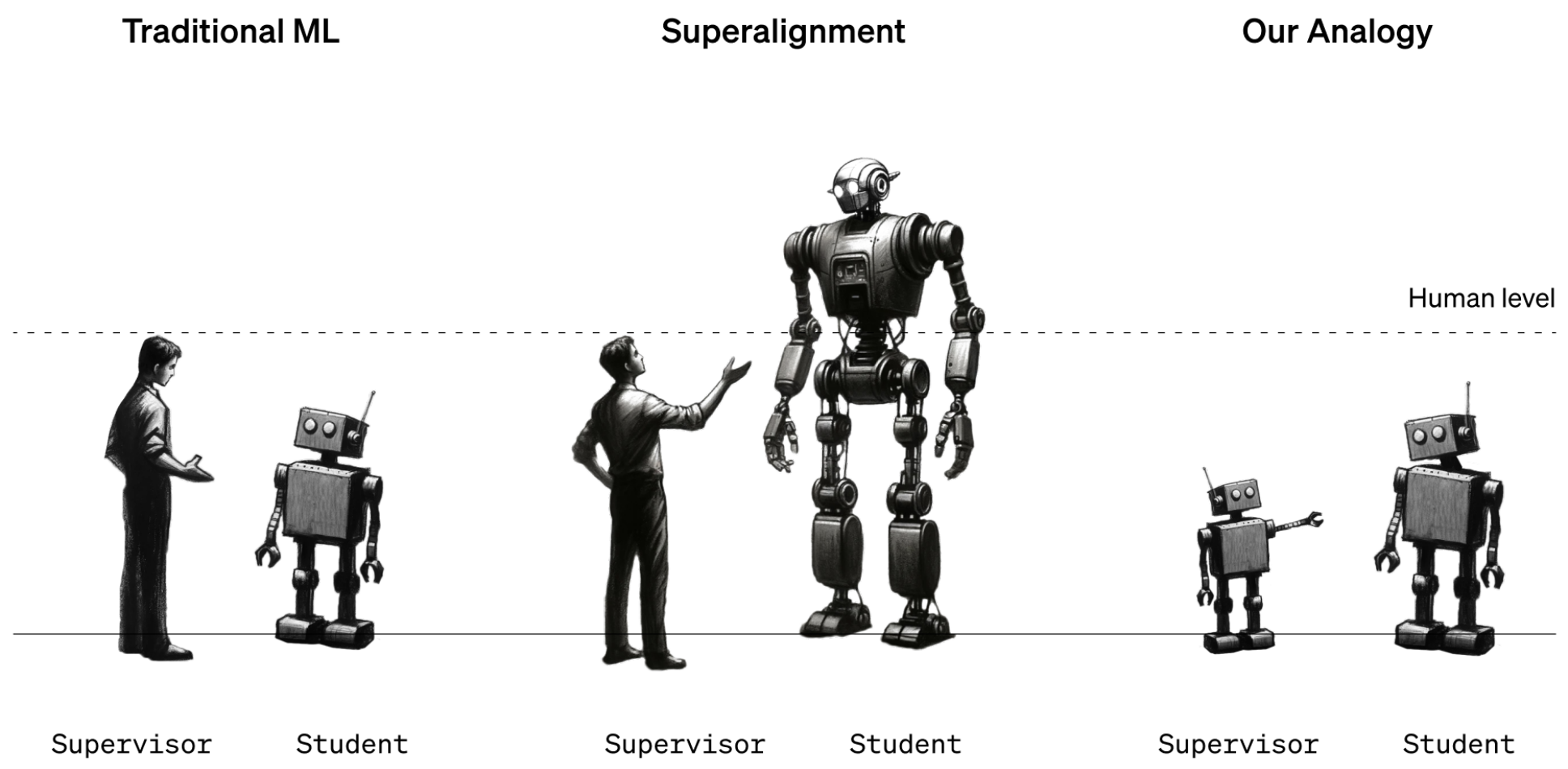
The researchers level out that the issue is difficult to check as a result of superhuman machines don’t exist. So that they used stand-ins. As a substitute of how people might supervise superhuman machines, they checked out how GPT-2, a mannequin that OpenAI launched 5 years in the past, might supervise GPT-4, OpenAI’s newest and strongest mannequin. “If you are able to do that, it is perhaps proof that you should utilize comparable methods to have people supervise superhuman fashions,” says Collin Burns, one other researcher on the superalignment crew.
The crew took GPT-2 and educated it to carry out a handful of various duties, together with a set of chess puzzles and 22 frequent natural-language-processing exams that assess inference, sentiment evaluation, and so forth. They used GPT-2’s responses to these exams and puzzles to coach GPT-4 to carry out the identical duties. It’s as if a twelfth grader had been taught methods to do a process by a 3rd grader. The trick was to do it with out GPT-4 taking too large a success in efficiency.
The outcomes had been blended. The crew measured the hole in efficiency between GPT-4 educated on GPT-2’s greatest guesses and GPT-4 educated on right solutions. They discovered that GPT-4 educated by GPT-2 carried out 20% to 70% higher than GPT-2 on the language duties however did much less properly on the chess puzzles.
The truth that GPT-4 outdid its trainer in any respect is spectacular, says crew member Pavel Izmailov: “This can be a actually stunning and optimistic outcome.” Nevertheless it fell far wanting what it might do by itself, he says. They conclude that the method is promising however wants extra work.
“It’s an attention-grabbing concept,” says Thilo Hagendorff, an AI researcher on the College of Stuttgart in Germany who works on alignment. However he thinks that GPT-2 is perhaps too dumb to be a very good trainer. “GPT-2 tends to offer nonsensical responses to any process that’s barely advanced or requires reasoning,” he says. Hagendorff wish to know what would occur if GPT-3 had been used as an alternative.
He additionally notes that this method doesn’t deal with Sutskever’s hypothetical situation wherein a superintelligence hides its true conduct and pretends to be aligned when it isn’t. “Future superhuman fashions will doubtless possess emergent skills that are unknown to researchers,” says Hagendorff. “How can alignment work in these instances?”
However it’s straightforward to level out shortcomings, he says. He’s happy to see OpenAI transferring from hypothesis to experiment: “I applaud OpenAI for his or her effort.”
OpenAI now desires to recruit others to its trigger. Alongside this analysis replace, the corporate introduced a new $10 million cash pot that it plans to make use of to fund individuals engaged on superalignment. It is going to supply grants of as much as $2 million to school labs, nonprofits, and particular person researchers and one-year fellowships of $150,000 to graduate college students. “We’re actually enthusiastic about this,” says Aschenbrenner. “We actually assume there’s quite a bit that new researchers can contribute.”
